
I had the privilege of attending ICLR 2026 this year thanks to generous support from UCB Sky Lab. I helped present Agentic Context Engineering at the main conference, as well as two oral presentations at the Lifelong Agent and MemAgent workshops. As a result, much of my experience centered on agent memory and continual learning. I am writing this reflection to summarize my takeaways from conversations with other researchers. I hope this blog strikes a chord with fellow readers and not with any companies’ legal teams over leaked information.
Reclassifying Evolving Agents or Continual Learning
 As these terms have become more popular, their classification has also become increasingly vague because they now appear in many different kinds of papers. I believe many of these works are actually targeting different use cases, even though they describe themselves as continual learning in the title.
As these terms have become more popular, their classification has also become increasingly vague because they now appear in many different kinds of papers. I believe many of these works are actually targeting different use cases, even though they describe themselves as continual learning in the title.
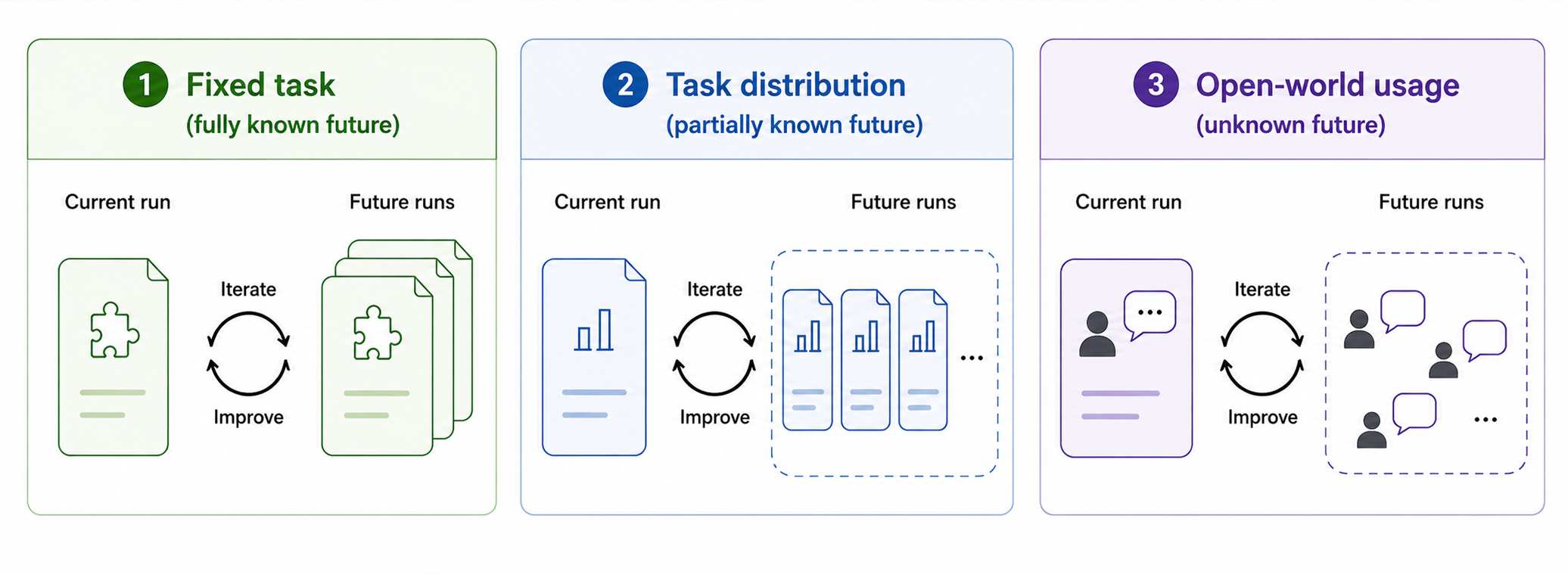
For example, consider two scenarios. In the first, an agent is trying to solve a particular task on a hard benchmark such as Frontier CS repo. The agent can iterate on its solution, and the goal is to achieve a better score on that specific problem. In the second, people are using ChatGPT, and we are trying to improve the model to increase user retention based on aggregate traces. Intuitively, these two scenarios are very different in both resource constraints and methodology. However, both could still be described as “evolving intelligence.” How should we distinguish them by looking at the problems themselves?
The most satisfying classification criterion I found is this: how much the agent assumes about future tasks while improving itself on the current one.
In an OpenEvolve-style Frontier CS setup, the agent is fully aware of the future problem it is trying to solve because that future problem is the same one. That makes repeated experimentation with solutions especially attractive. All of the takeaways accumulated in the current run will be directly applicable in future runs.
In evaluation setups such as those used in ACE, Combee, or GEPA, future knowledge is limited to the problem type; the full task description is not available during the update process. For example, we might train on a specific agent use case, such as a finance-domain task, to generate a system prompt. This makes overfitting a real concern compared with the previous case, but the agent does not need to improve its general problem-solving ability. It only needs to adapt to a specific class of problems.
For the more general case of Cursor or ChatGPT updating its model checkpoint for all users, the scenario is different again. Probably the only assumption we can make about future tasks is that users will continue to ask coding or personal-assistant-style questions. This means that task-specific details generated in each scenario should probably be omitted, since the exact same task is unlikely to be repeated. In this case, updating the weights is probably the most effective approach.
These three examples suggest that if we make our assumptions about future task knowledge explicit, the problem of continual learning or self-improving agents can be separated more cleanly into categories. That could reduce confusion in discussions and peer review.
The Three Pillars of Evolving Agents: Models, Harness, and Environments
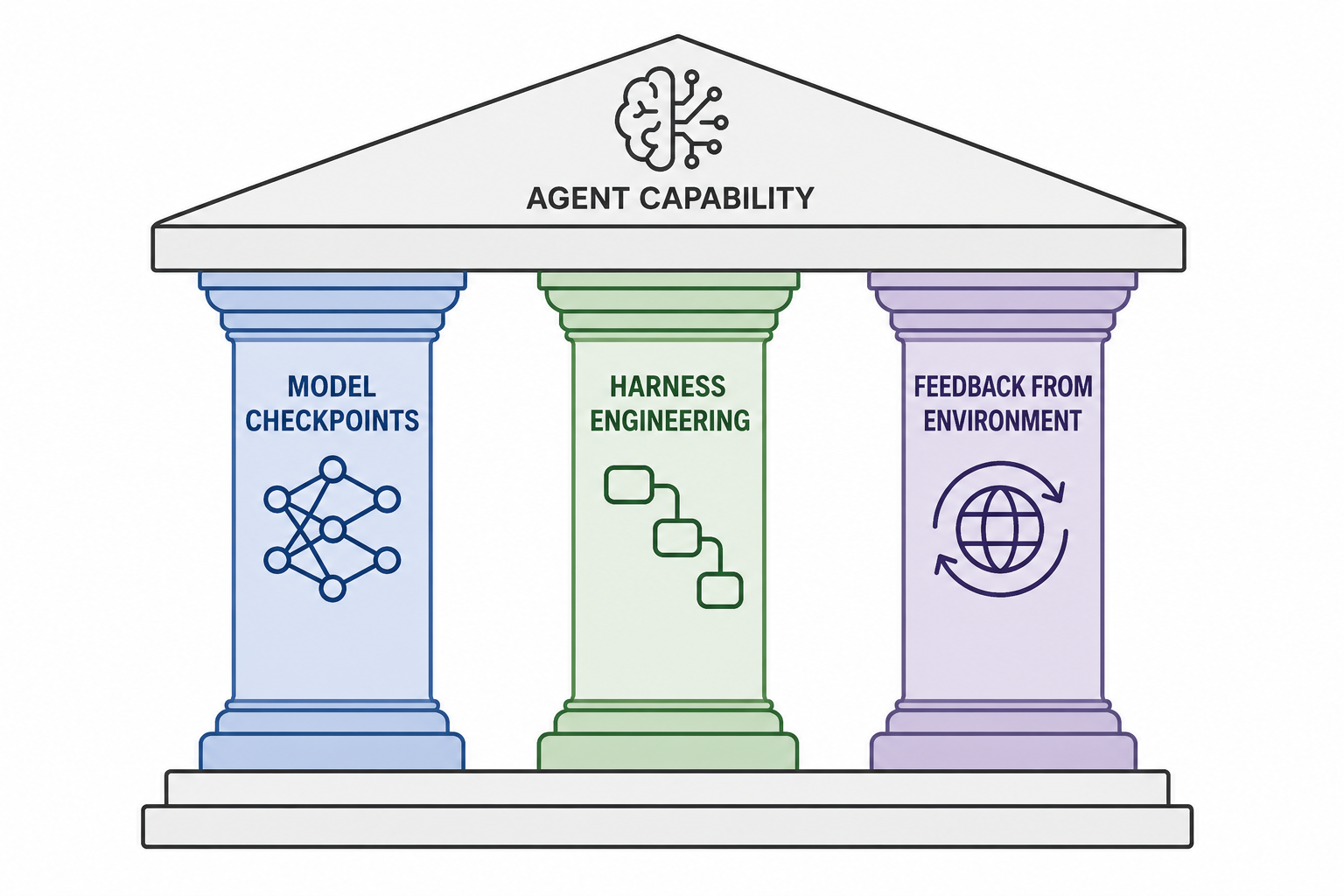 In one of my conversations after the MemAgent workshop, another researcher proposed a useful way to think about different directions for improving agents: model checkpoints, harness engineering, and feedback from the environment. It was a short discussion, but I found the three pillars highly compelling. I am reusing that abstraction here while filling in my own understanding.
In one of my conversations after the MemAgent workshop, another researcher proposed a useful way to think about different directions for improving agents: model checkpoints, harness engineering, and feedback from the environment. It was a short discussion, but I found the three pillars highly compelling. I am reusing that abstraction here while filling in my own understanding.
Model checkpoints are the foundation of agents. They are simply the base LLMs running on inference engines.
Harness and environment are often discussed together, but improvements in retrieval models can hardly be classified as harness engineering. So it is useful to separate them. The distinction is that the harness determines the format of inputs to the model checkpoint, while feedback from the environment determines the content of those inputs. For example, adding a step that incorporates skills into an agent would be harness engineering, while determining how to retrieve the relevant skill, for instance through RAG, would fall under the environment.
In many scenarios, harness engineering methods are really patchwork fixes for model checkpoints. For example, one reason to spin up sequential subagents is that the model becomes forgetful and inefficient as context length grows. In an ideal world where recurrent architectures worked perfectly, an agent could simply keep feeding text into the model. We would not need methods like ACE if models could internalize all of their past experience on their own. The very fact that these methods exist suggests that our current model checkpoints still lack those capabilities.
Unfortunately, model checkpoint updates move much more slowly than harness changes. How much will the next generation of models fix these capability gaps? We will have to wait for the frontier labs to find out. But the final landscape may look something like a meta-harness that rapidly adapts to new models before the models update their weights again.
On the other hand, feedback from the environment remains irreplaceable. If a model has never had access to the news, it simply cannot respond to it.
Acknowledgement
This blog was mainly written on Hanchen’s flight back from Panama City to SFO. This time, Claude Code was locked away in the cyber void. The ideas here come from discussions with people I met at the conference, including but not limited to Idan, Benjamin, Yihao, and Qizheng.