CES and Groq "Acqui-hire" Reflection: Nvidia's Plan to Build Real Time Agents?
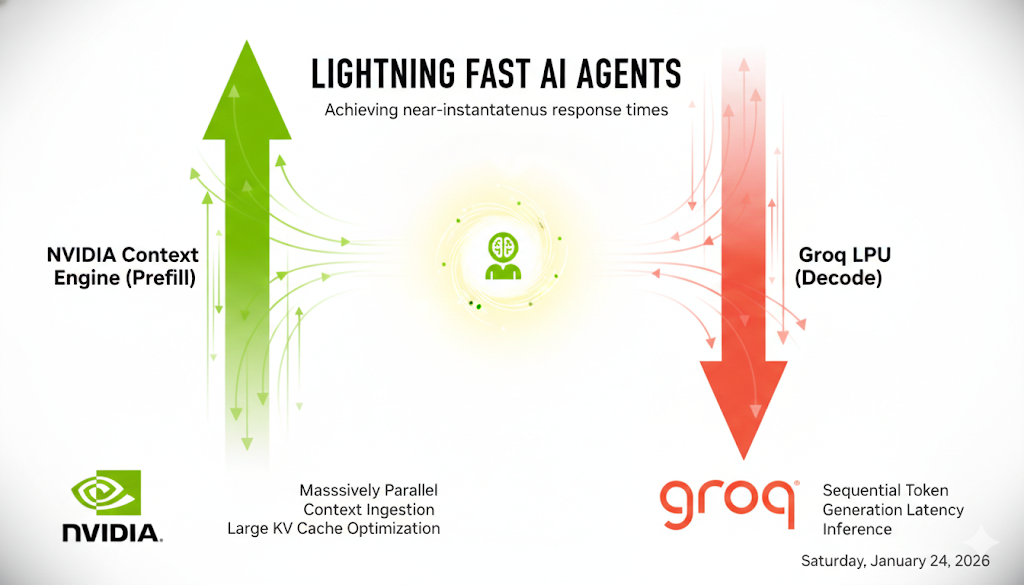
In this blog post, we will discuss Nvidia’s recent announcements at CES and their strategic partnership with Groq, focusing on their strategy to enhance LLM agent inference. We will explore three main aspects: the importance of KV cache hits, the role of SRAM in improving decoding speed, and a proposed hardware-software architecture that potentially speeds up agent inference to real-time. Prerequisite: LLM inference basics. Suggested reading: LLM Inference; KV Cache Offloading with LMCache; LLM Agent with KV Cache ...